
The Multiplicity Problem in Interpreting Model Internals
Why Model Internals are Arbitrary (and How to Fix Them)

Recently, I had the opportunity to give a guest lecture at Lesia Semenova’s IXAI course at Rutgers, about the failures of feature attribution methods. The session helped me articulate a fundamental issue in post-hoc interpretability: the multiplicity problem. We train models to minimize loss on outputs, yet we rely on internals—features and gradients—to interpret behavior. This is a flawed enterprise when different internal structures represent the same model behaviour, but lead to different interpretations.
Gradient Multiplicity: In the guest lecture, I talked about a lot of my own work which demonstrates multiplicity in model gradients. The issue is quite severe, yet easy to understand: we can have two models f_1(x) and f_2(x) that both agree on infinitely many pointwise predictions, yet diverge significantly in their gradients. This explains many “unreliability“ results in the feature attribution literature, where gradients can be arbitrary manipulated, or where gradients are found to be unfaithful to model behaviour.
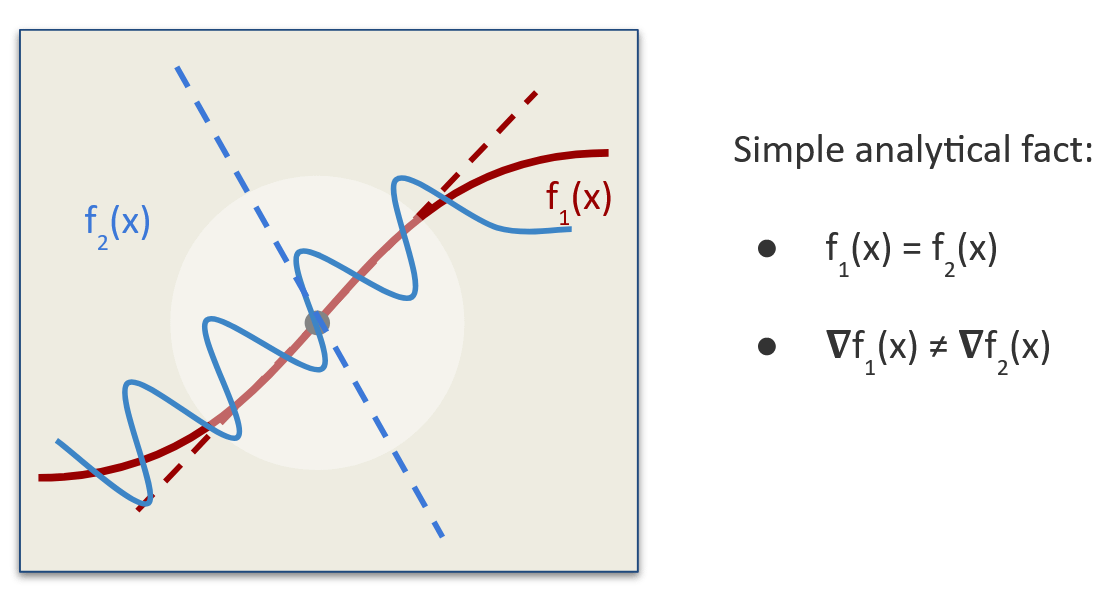
Fortunately, there’s a simple fix: constraint the model to be robust, ensuring that the model is as smooth as possible. Enforcing smoothness ensures gradients are less arbitrary, and it turns out that this unlocks a lot of interesting properties, making gradients more “perceptually aligned“. Sebastian Bordt and I wrote a paper on this phenomenon back in 2023.

This demonstrates something remarkable, that gradients of standard models do not carry much structure naturally, but regularized training can help structure to emerge!
Feature Multiplicity: Neural network features are inherently arbitrary; a complex invertible transform can make a representation unintelligible without altering the model's functionality. This is an obvious and somewhat well-known fact1. Yet, many approaches to mechanistic interpretability study features as a fundamental object.
There are some ad-hoc justifications in the literature claiming a lack of multiplicity. One is the idea of “privileged basis“, which states that “some aspect of a model’s architecture encourages neural network features to align with basis dimensions, for example because of a sparse activation function such as ReLU“. Another is the idea of “linear representation hypothesis“, which states that high-level concepts are linear functions of features. These are important observations, but relying on accidental structure to interpret models makes them prone to failure.
How to fix this? From analogy to gradient maps, it is clear that one path forward might be to regularize models — perhaps using smoothness constraints or architectural priors — during model training. The objective here is to mitigate the multiplicity issue, by careful model design. The exact details of how to do this is, and which regularizers are most useful, is an important open question. But, the overall goal must be to make interpretability feasible by design rather than hoping that it arises naturally2.
I wrote a blogpost about this 2+ years ago: https://surajsrinivas.substack.com/p/is-mechanistic-interpretability-feasible
For CoT explanations, it turns out that training for CoT monitorability has started to become a thing. Yay!
Interesting point. I agree with overall premise that encouraging smoothness is a good thing to do from an interpretability perspective! Also very big on the idea of encouraging for CoT monitorability / LLM faithfulness in general.
I would say in terms of framing, that the problem is less about models that "agree at infinitely many points" and more about models that "agree nearly everywhere of interest".
In both of those papers from the course notes, LIME/Gradients are basically measuring how the model behaves in OOD regions that we don't actually care about (either unlikely tabular examples or arbitrary directions off of the image manifold), so we can change its behavior in this OOD regime without noticing. I guess this ties in with your paper about off-manifold robustness.
Final thought: You said "We train models to minimize loss on outputs, yet we rely on internals—features and gradients—to interpret behavior." Have you ever thought about trying to tackle some of these problems through looking at the location of the model on the loss-landscape instead? I was talking with Jesse Hoogland, founder of https://timaeus.co/ a while back, and he was saying his company has a few projects in this direction.
Cool perspective! Does the multiplicity problem persist in interpretability methods like integrated gradients that have a specific reference comparison point?
Also, do you have any resources for implementing some of these solutions for building more robust models?