
Explainability Research Must Focus on Foundations rather than Ad hoc Methods
An ICML 2026 paper explainer and retrospective


Our position paper on "explainability research must focus on foundations rather than ad hoc methods" will be presented next month at ICML 2026. This work was a fantastic collaboration with a brilliant and diverse group of researchers across academia and industry, and was genuinely a blast to work on. In this blogpost, I want to explain why we wrote this paper, and what you can take away from it. These are my personal reflections, and may not necessarily reflect the opinions of my co-authors.1
Our story starts at NeurIPS 2023, where a bunch of us (Michal, Nave, Chhavi, Bingqing, Valentyn, and myself) organized an Explainable AI workshop, called “XAI in action”. At the time, we observed that plenty of XAI "methods" papers were being published at top conferences, but far fewer on their practical real-world impact. Authors commonly motivated work by claiming uses in "high-stakes critical applications" or for "increasing user trust," but we saw very few real demonstrations. With this workshop, we wanted to give visibility to such applications-oriented work. While the workshop was a success, we were surprised by how few applications papers were submitted despite our explicit focus. There were a few standouts though, with my favorite paper improving solar cell manufacturing using XAI. This position paper is a reflection of what we saw at that and our follow-up workshop at NeurIPS 2024 on intrinsically interpretable models (where Lesia joined us).
We observed some recurrent issues: there were an overwhelming number of papers proposing new methods, but far fewer papers on real applications, or theoretical work on understanding their limits. We first thought to write a retrospective documenting these observations, but we soon realised this was endemic to the whole field. In the position paper, we performed an LLM-driven survey of XAI papers2 at ICML / NeurIPS / ICLR, and found that most accepted papers propose new methods, and very few think about applications, evaluations or definitions. We found this concerning. Despite thousands of papers on feature attribution or concept-based methods / SAEs, the field has yet to converge on a single definition, or gold-standard evaluation(s) for their fundamental ideas. Some examples below:


Without a concrete conceptual basis (definitions, evals) or a clear connection to real-world tasks, it becomes hard to even answer the question: "has XAI made any meaningful progress?" We might know more about the mechanics of specific methods (feature attribution, SAEs), but can we do anything new with these tools that is hard to do otherwise? Have we made any quantifiable claims about models that have held up? I'm not sure.
Maybe the absence was just a matter of visibility. We thought perhaps all the impactful XAI applications work was hiding behind closed doors in industry, or in various applied domains in academia. To test this hypothesis, we ran a user survey of XAI researchers across academia and industry. We found that while researchers are somewhat optimistic about these tools, they derive value (if they do at all) through ad-hoc means, and have no way of quantifying the benefits they supposedly achieve.
Some of these fundamental issues are growing pains of a nascent field. And we think the way to resolve this is to focus on foundations rather than ad-hoc methods. Specifically, we think progress on the four interdependent challenges described in the figure below would be most fruitful.
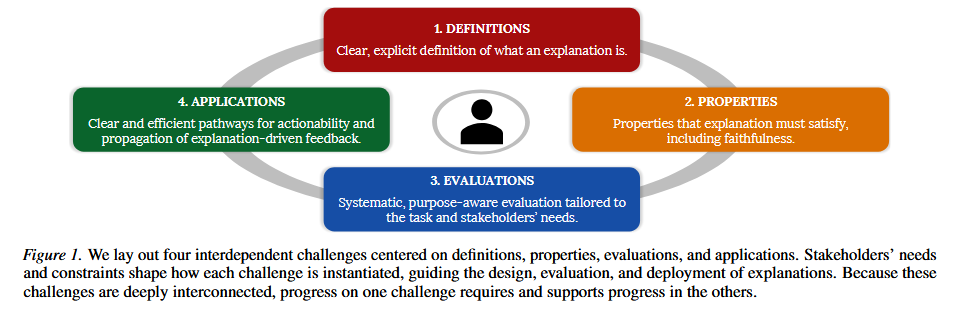
These challenges include what we believe are the foundations of the field — definitions, properties, evaluations, and applications. For XAI, none of these are quite clear, and thus no quantifiable progress can happen.
How to move towards this goal to build better foundations? We propose that you ask yourself whether your next XAI paper satisfies the following criteria:

The point here is not that your paper is bad if it doesn't have all these elements3. Maybe some don't apply, or maybe addressing some would be too hard right now. That's fine. We're not perfect either; our own papers don't necessarily satisfy these criteria! But the idea is that if we can slowly start including these elements, the field will eventually make measurable progress.
In computer vision, the ImageNet classification challenge became the benchmark for progress. Everybody agreed that progress on ImageNet meant progress on computer vision. I hope XAI can eventually do the same: that we pose a well-defined challenge, and that progress on it means progress on interpretability and understanding model internals. We won't achieve these goals until we can agree on what they should be in the first place, and that starts with the foundations.
A brief note on terminology, “XAI” will refer to both explainable AI and interpretability. Some folks use them interchangably whereas others assign strict non-overlapping meaning to them. I will fall in the first camp in this blogpost to align with popular usage.
XAI papers = papers that self-report to be about explainability or interpretability. Note that there is no other criteria to filter papers, highlighting yet another problem with the terminology: a paper automatically becomes an interp paper if it is says so.
Maybe except the second checkpoint list. If your paper makes claims that are not easily falsifiable, then you should consider removing them.